
Import XML souborů s HTML tagy do MemoQ
Tento článek je určen překladatelům, kteří se potýkají se zapeklitostmi formátu .xml. Nedávno jsem dostala k překladu XML soubor, který navíc obsahoval HTML tagy (jednalo se o webové stránky). Sice by bylo možné přeložit dokument i po jednoduchém importu do CAT nástroje (v mém případě MemoQ), ale text obsahoval množství nezpracovaných tagů, které by nejen že vadily při práci, ale také neumožňovaly přesnou kalkulaci počtu slov. Použila jsem proto kaskádové filtry, které zpracovaly jak XML, tak HMTL tagy. Postup je následující:
1. Vytvořte nový projekt a nahrajte dokument. Pokud jste jej již do MemoQ naimportovali, použijte opětovný import (Reimport document na stránce Project Home).
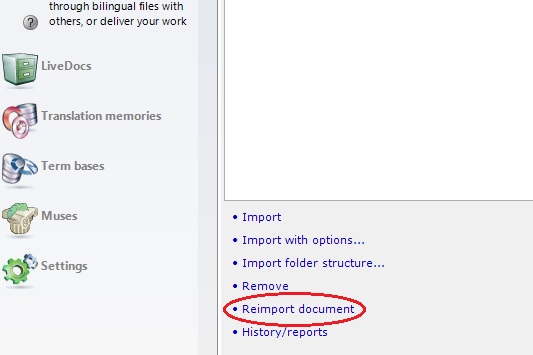
2. Pokud se někdy připojujete k serverovým pamětem, ale tentokrát pracujete pouze s vlastními zdroji, nezapomeňte nahoře na stránce nastavit možnost My Computer (v opačném případě bude MemoQ hledat kaskádové filtry na serveru).
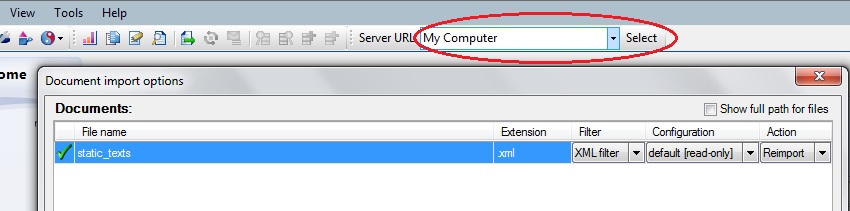
3. V dolní části dialogového okna Document import options klikněte na Change filter and configuration.
4. V okně Document import settings klikněte na kartuTags and attributes a poté na tlačítko Populate.
.jpg)
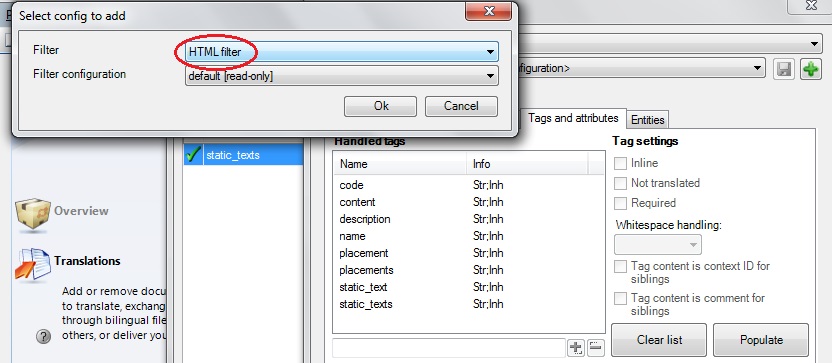
5. Nad záložkami klikněte na modré Add cascading filter … a v novém dialogu vyberte ze seznamu možnost HTML filter (protože filtr XML už jste nastavili v předchozích krocích).
6. Pod příkazem Add cascading filter … klikněte na HTML filter tak, aby byla tato možnost v oranžovém písmu, ponechejte možnost Import markup as inline tags a klikněte na OK (pokud chcete, zaškrtněte nebo odškrtněte další možnosti dle potřeby).
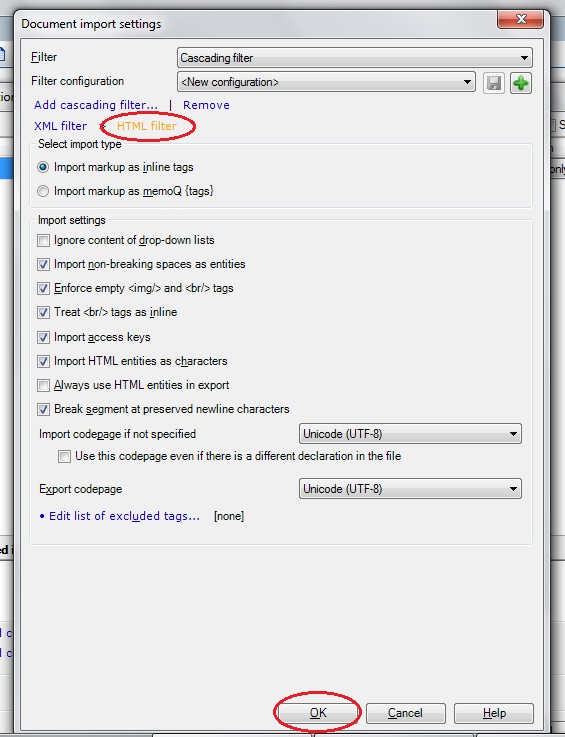
7. Vrátíte se na dialog Document import options a teď už jen stačí kliknout na OK. Import dokumentu se dokončí.
8. V textu by se vám teď místo kódu ve špičatých závorkách a dalších nadbytečností měly objevit malé modré značky, s nimiž se velmi lehce pracuje a nehrozí, že kód poškodíte nebo zapomenete.

Jak už bylo řečeno v úvodu, zpracovávala jsem tímto způsobem webovou stránku, ale v závislosti na redakčním systému zadavatele se k vám takový soubor může dostat třeba jen ve formátu HTML – práci tak budete mít jednodušší. Popsaný postup se týká souborů, které kombinují jak XML, tak i HTML tagy. V neposlední řadě bych chtěla vyzdvihnout funkci Reimport document, která vám umožňuje provádět rychlé změny importovaného souboru. S touto funkcí jsem v Tradosu nesetkala a dávám za ni programu MemoQ velké plus.
Doufám, že vám článek přinesl užitek a pokud se tento postup osvědčil (nebo s ním naopak máte problémy), zmiňte se v komentáři.
- 21 Říj, 2013
- Napsala Zuzana Novotná
- 0 Komentáře
KOMENTÁŘE